
前言
可能是在整理
基本上把能看的学习笔记集中在这里, 这样就不会混乱了, 打起来也不用
(肝)
前置知识
#define N 100000 // 代表数据范围(可以修改的)
#define il inline //内建函数, 防止卡常用(大多情况下可以不用用到)
#define cl(a,b) memset(a,b,sizeof(a)) //清空数组用, a = 对象数组名, b = 数值(不大于一个字节)
typedef long long ll; //重定义 long long 关键字为 ll
typedef unsigned long long ull; //重定义 unsigned long long 关键字为 ull
栈

介绍
栈是常用的一种线性数据结构,修改是按照后进先出的原则进行的,又被称为是后进先出(
可支持操作
bool empty() 判断栈是否为空
void pop() 弹出栈顶元素
int top() 返回栈顶元素
void push() 插入元素于栈顶
int size() 返回栈大小
void clear() 清空栈
复杂度
插入/弹出
访问最顶元素
手写栈
struct Stack
{
int val[N],tot;
Stack() { cl(val,0),tot=0; }
void clear() { tot=0; }
int pop() { return tot==0?0:val[tot--]; }
int top() { return val[tot]; }
void push(int x) { val[++tot] = x; }
int size() { return tot; }
bool empty() {return tot==0; }
}s;
例题
P3015 [USACO11FEB]Best Parenthesis S
Sth
一般来说, 栈作为最最最基础的数据结构之一, 往往不会单独考察, 只会借助 LIFO 的优势, 对一些问题辅助求解, 当然这要求你对其很熟悉。
队列

介绍
队列, 顾名思义就是一个有顺序性质的数据结构, 与栈的实现方式略有不同, 修改是按照先进先出的原则进行的, 也被称为先进先出(
可支持操作
void push() 插入元素于队头
void pop() 弹出队尾元素
int front() 返回队头元素
int back() 返回队尾元素
int size() 返回队列大小
bool empty() 判断队列是否为空
void clear() 清空队列
手写队列
struct Queue
{
int val[N],l,r;
Queue() { cl(val,0),l=1,r=0; }
void push(int x) { val[++r]=val; }
int pop() { return val[l++]; }
int front() { return val[l]; }
int back() { return val[r]; }
void clear() { l=1,r=0; }
int size() { return r-l+1; }
bool empty() { return (r-l+1)==0; }
}q;
例题
Important 此处需要更新
Sth
与栈相同, 作为最基础的数据结构, 一般只作为辅助算法, 很少单独考察
树链剖分
介绍
树链剖分用于将树分割成若干条链的形式, 以维护树上路径的信息。
具体来说, 通过轻重边剖分将整棵树剖分为若干条链(是每个节点只属于一条链), 把树形结构变为线性结构, 然后用其他的数据结构(树状数组, SBT, Splay, 线段树)维护每一条链上的信息(本质上是一种优化暴力)。
思想
你首先需要知道以下知识:
重子节点(重儿子):其子节点中子树最大的子节点。如果有多个子树最大的子节点, 取其一。如果没有子节点, 就无重子节点。
轻子节点(轻儿子):父亲节点除重子节点外的所有子节点。
重边:父亲节点到重子节点的边。
轻边:父亲节点到其他轻子节点的边。
重链:由多条重边连接而成的路径(链)。
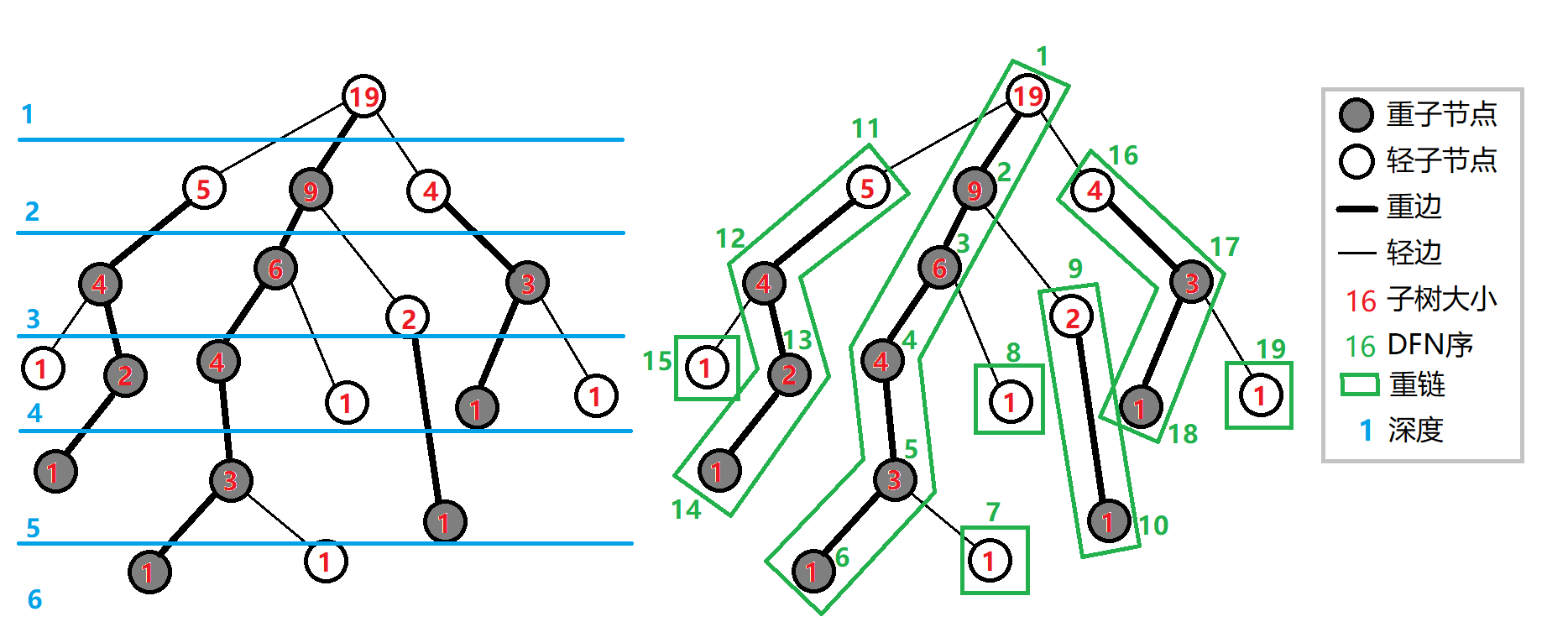
比如上面这幅图中, 用 黑线(加粗线) 连接的节点都是 重节点, 其余均是 轻节点 。
在树链剖分中, DFN 序 一般指的是 按照重链优先原则 的深度优先搜索的顺序。
可以看到在访问完一个节点的时候, 会 优先访问其重子节点 ,
到达 叶子节点 的时候, 一条重链就形成了,
然后开始递归, 寻找上个节点的 轻节点 , 并由这个轻节点开始, 再 访问其重子节点 ...
那么可以知道每一条链都是由 轻节点作为其顶端节点 ,然后 余下的节点都是父节点的重子节点 (存在没有子节点的情况),所以你可以把一颗树上都每一个节点都划分到一条链中(如图)。
DFN 序是 按照重链优先原则 的深度优先搜索的顺序 到达叶子节点的时候, 一条重链就形成了, 然后开始递归, 寻找上个节点的轻节点, 并由这个轻节点开始, 再访问其重子节点...
由上述的两个事情可以发现一个事情,你在不断dfs的过程中,你会将 一个子树内的节点 划分到 DFN序列的连续一块 ,你也会将 一条链 划分为 DFN序列的连续一块 。
这样使得查询和修改变得容易起来, 我们就可以用数据结构维护这一个 DFN 序列。
( 那么, 你怎么知道这个节点的 重子节点 呢 ? )
初步实现
我们需要两次 DFS 预处理这些值,先得到重儿子才能做树链剖分
前置定义
vector<int> mp[N]; //本文使用vector存边
int size[N], dep[N], fa[N], son[N];
int id[N], rev[N], top[N], tot;
fa[x] x dep[x] x size[x] x son[x] x top[x] x id[x] x rev[x] rev[id[x]]=x
第一次dfs
- 我们在第一次 DFS 中, 找该节点的 重子节点
son[x] size[x] fa[x] dep[x]
il void dfs1(int u, int f) // u为当前节点, f为当前节点的父节点
{
size[u] = 1; // 初始化当前子树大小
fa[u] = f;
dep[u] = dep[f] + 1;
for (int i = 0; i < mp[u].size(); i++)
{
int v = mp[u][i];
if (v == f) continue; // 防止死循环, 自证不难
dfs1(v, u);
size[u] += size[v]; //统计子树大小
if (size[v] > size[son[u]] || !son[u]) son[u] = v; //寻找重子节点
}
return;
}
第二次dfs
- 第二次dfs中, 我们按照 重链优先原则 进行 DFS , 这棵树进行剖分, 对于每个节点所属的链, 我们做出这样安排, 将这条重链的 顶端节点
top[x] - 然后我们还要生成 DFN 序列
id[x] rev[x]
il void dfs2(int u, int t) // u为当前节点, t为当前节点所在链的顶端节点
{
top[u] = t;
id[u] = ++tot; // 将id序列下一个编号赋予给这个节点
rev[tot] = u; // rev[id[x]]=x
if (!son[u]) return; // 没有儿子的情况
dfs2(son[u], t);
/*我们选择优先进入重儿子来保证一条重链上各个节点DFN序连续,
一个点和它的重儿子处于同一条重链,所以重儿子所在重链的顶端还是t*/
for (int i = 0; i < mp[u].size(); i++)
{
int v = mp[u][i];
if (fa[u] != v && son[u] != v) dfs2(v, v);
// 对于每一个轻儿子,这个轻儿子所属的顶端节点就是它本身
}
return;
}
性质&复杂度
树链剖分拥有它独特的性质
树上每个节点都属于且仅属于一条重链
重链开头的结点不一定是重子节点。
所有的重链将整棵树 完全剖分。
在剖分时 重边优先遍历,最后树的 DFN 序列上,重链内的 DFS 序是连续的。
按 DFN 排序后的序列即为剖分后的链。
一颗子树内的 DFN 序是连续的。
对于每一个轻子节点,
从任意一个节点到根节点经过轻重链的个数不超过
所以树链剖分的时间复杂度为
实际应用
树链剖分一般服务于
代码
vector<int> mp[N];
struct Tree
{
int l, r, val, maxn;
};
#define ls(x) (x<<1)
#define rs(x) ((x<<1)|1)
struct SeG
{
Tree t[N<<2];
int w[N];
il void pushup(int x)
{
t[x].val = t[ls(x)].val + t[rs(x)].val;
t[x].maxn = max(t[ls(x)].maxn, t[rs(x)].maxn);
return;
}
il void build(int x, int l, int r)
{
t[x].l = l, t[x].r = r;
if (l == r)
{
t[x].maxn = t[x].val = w[l];
return;
}
int mid = (l + r) >> 1;
build(ls(x), l, mid);
build(rs(x), mid + 1, r);
pushup(x);
return;
}
il void change(int x, int k, int num)
{
if (t[x].l > k || t[x].r < k) return;
if (t[x].r == k && t[x].l == k)
{
t[x].val = t[x].maxn = num;
return;
}
change(ls(x), k, num);
change(rs(x), k, num);
pushup(x);
return;
}
il int ask_m(int x, int l, int r)
{
if (t[x].l > r || t[x].r < l) return -INF;
if (t[x].l >= l && t[x].r <= r) return t[x].maxn;
return max(ask_m(ls(x), l, r), ask_m(rs(x), l, r));
}
il int ask_v(int x, int l, int r)
{
if (t[x].r < l || t[x].l > r) return 0;
if (t[x].r <= r && t[x].l >= l) return t[x].val;
return ask_v(ls(x), l, r) + ask_v(rs(x), l, r);
}
};
struct TLC
{
int size[N], dep[N], fa[N], son[N];
int id[N], rev[N], top[N], tot;
SeG tree;
il void dfs1(int u, int f) // u当前节点,f=fa[u]
{
size[u] = 1;
fa[u] = f;
dep[u] = dep[f] + 1;
for (int i = 0; i < mp[u].size(); i++)
{
int v = mp[u][i];
if (v == f) continue;
dfs1(v, u);
size[u] += size[v];
if (size[v] > size[son[u]] || !son[u]) son[u] = v;
}
return;
}
il void dfs2(int u, int t) // u当前节点,t=top[u];
{
top[u] = t;
id[u] = ++tot;
rev[tot] = u;
if (!son[u]) return;
dfs2(son[u], t);
for (int i = 0; i < mp[u].size(); i++)
{
int v = mp[u][i];
if (fa[u] != v && son[u] != v) dfs2(v, v);
}
return;
}
il int qMax(int x, int y)
{
int ans = -INF;
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]]) swap(x, y);
ans = max(ans, tree.ask_m(1, id[top[x]], id[x]));
x = fa[top[x]];
}
if (dep[x] > dep[y]) swap(x, y);
return max(ans, tree.ask_m(1, id[x], id[y]));
}
il int qSum(int x, int y)
{
int ans = 0;
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]]) swap(x, y);
ans += tree.ask_v(1, id[top[x]], id[x]);
x = fa[top[x]];
}
if (dep[x] > dep[y]) swap(x, y);
return ans + tree.ask_v(1, id[x], id[y]);
}
il void change(int x, int num)
{
tree.change(1, id[x], num);
return;
}
} a;
